
/* h2 {
text-align: center;
} */
p {
text-indent: 2em;
text-align: justify;
line-height: 30px;
}
/* 为图片和文字设置布局样式,左图右字 */
/* .profile-container {
display: flex;
align-items: center;
justify-content: space-between;
padding: 20px;
gap: 20px;
border: 1px solid #ddd; 可自定义边框样式
} */
.profile-description {
flex: 1;
/* margin-right: 30px; */
text-align: justify;
}
/* img.profile-image {
max-width: 150px;
height: auto;
border-radius: 5px;
} */
/* 清除段落间距 */
* {
margin: 0;
padding: 0;
}
h3 {
text-align: center;
}
AI算法与芯片架构
论坛简介
算力芯片是AI实现的硬件基础,智能系统是AI场景落地的具体载体,大模型是AI实现的灵魂。本次论坛特邀学术界和产业界著名专家和学者介绍算力芯片、智能系统、大模型和数据安全等方向的最新进展,深入交流AI在不同场景中的落地方法。
论坛日程
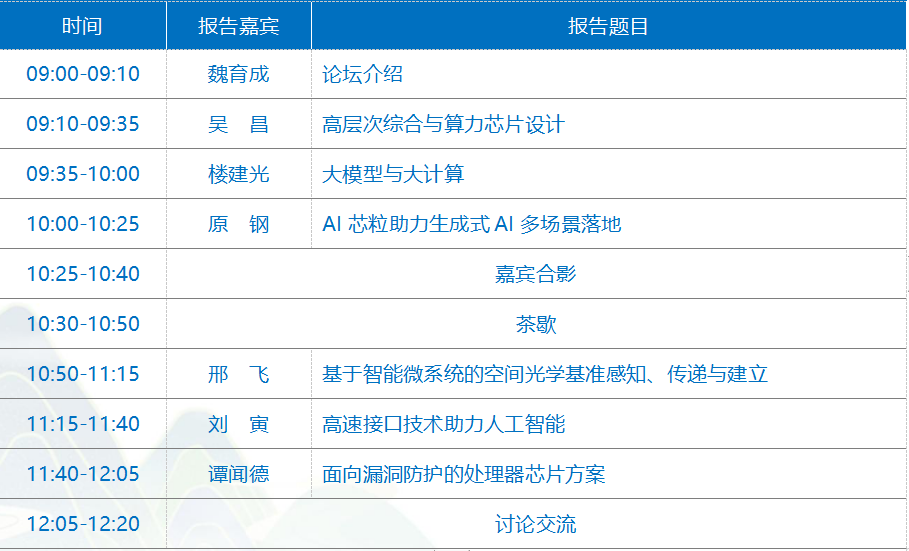
论坛主席

魏育成
CSIG理事,中科亿海微总裁
个人简介:魏育成,博士,教授级高工,现任中科亿海微电子科技(苏州)有限公司总裁。多年致力于人工智能、数据资源共享与服务、智能芯片等方面技术研究和产业化工作,其研究成果已在智能制造、现代通信、能源电力、轨道交通、数据中心、金融科技等领域得到有效验证与市场应用。荣获华夏建设科学技术奖、中国科学院科技成果转化奖、国科大杯创新创业一等奖,是中国半导体行业协理事、科技部专家库成员。
报告嘉宾

吴 昌
复旦大学研究员
报告题目:高层次综合与算力芯片设计
报告摘要:人工智能技术的发展带来了算力芯片的巨大需求。工信部的报告预测2025年我国人工智能算力芯片的需求达2600亿人民币。另一方面,2023年智能计算白皮书显示全球的算力需求里面,通用算力需求占比约75%,智能计算算力占比则为20%。智能计算算力目前主流是GPU芯片,而通用计算算力主要靠CPU、FPGA和SOC来完成。其中,FPGA与SOC因其高性能、高能效及低延迟,无论在通用算力计算和人工智能计算上都是一个重要的技术方案。为了发展FPGA与SOC的算力芯片,高层次综合成为了一个至关重要的软件工具,其重要性等同于GPU的开发软件平台cuda。高层次综合因其能够提供快速算法设计综合、自动电路体系结构设计以及更快速的仿真验证,成为了一个算力芯片设计时代的新型EDA技术。我们从算法的并行化计算、自动流水线设计、数据流计算几个方面介绍高层次综合的最新技术发展,展示其在算力芯片设计的巨大作用。考虑到我国FPGA产品的发展远比GPU的发展更为成熟,以HLS支撑的FPGA算力解决方案将可以弥补我们的GPU产品发展上的短板。
我们最新的研究显示高层次综合在多芯粒设计上比RTL设计更具有显著的技术优势。我们在多FPGA系统和2.5D FPGA上分析了基于高层次综合的系统划分及互联优化算法。在多FPGA系统上,我们的算法可以取得对比新思科技的HAPS软件10x的性能提升。在2.5D FPGA上,我们的算法可以取得对比AMD的Vivado软件65%的时钟频率提升和55%的计算性能提升。我们相信在人工智能时代,高层次综合技术将超越RTL设计技术,成为算力芯片设计的主流技术。
个人简介:吴昌,复旦大学研究员,博导,FPGA与高性能计算实验室主任。曾参与了国家EDA熊猫系统的科技攻关工作。主持研发了国产FPGA全流程EDA软件工具。曾获ACM协会FPGA20(1992-2011)杰出论文奖、上海科技发明一等奖、上海市优秀产学研项目特等奖。研究领域包括RTL综合、高层次综合、逻辑优化、FPGA工艺映射、系统划分与互联架构优化、智能计算加速器设计与优化等。

楼建光
微软亚洲工程院首席研究员
报告摘要:介绍大模型的当前发展现状,其训练和推理对计算带来的需求与挑战,以及针对计算问题的一些相关研究与实践,并在此基础上对未来的发展进行展望和探讨。
个人简介:楼建光,博士,微软工程院首席研究员,CCF系统软件专委委员。近年来主要从事自然语言理解、人工智能和模型调优方面的算法研究,及其在交互式数据分析机器人、基于大模型自动程序生成、平面设计智能化、大规模在线系统运维等方面应用工作。多项成果在微软公司的产品实践中得到广泛应用,部分工作发表在人工智能、自然语言处理、计算机软件、系统及数据挖掘相关的知名国际会议。

原 钢
原粒(北京)半导体技术有限公司,联合创始人/COO
报告题目:AI芯粒助力生成式AI多场景落地
报告摘要:近年来大模型和生成式AI已成为人工智能技术中最热门的领域,各种新的算法及应用层出不穷。大模型和生成式AI的计算需求庞大,对云端以及边缘端算力提出了很高的要求,生成式AI的多场景落地离不开降低成本和提高能效比这两个重要的前提条件。芯粒(Chiplet)技术作为后摩尔时代硅基芯片进一步提高计算密度和降低制造成本的几乎唯一路径,得到了产业界的广泛重视。AI芯粒以芯粒的形式提供灵活的AI算力配置和应用场景方案,将为生成式AI技术的多场景落地提供有力支撑。
个人简介:原钢,原粒(北京)半导体技术有限公司联合创始人,研究生毕业于中国科学院半导体研究所,超过20年的芯片行业从业经历,在集成电路设计、FPGA异构加速、AI算法部署应用等领域有丰富经验,曾就职于AMD/Xilinx、深鉴科技、芯原微电子、苏州中科半导体等国内外著名芯片公司。

邢 飞
清华大学教授
报告题目:智能微系统及端侧视觉感知技术
报告摘要:端侧智能模块采用标准化可复用传感层与处理层SIP的层级架构设计,融合端侧数据处理硬件加速核、轻量型智能算法与特征级自动化算法,以第2代微铜柱TMV工艺标准接口实现层间互联,通过传感层CMOS单元与处理层FPGA/SOC单元堆叠结构进一步优化布局尺寸,形成具有高功能密度、高导电导热率、SIP+TMV级封装的端侧智能模块最小核心微系统,尺寸小于10mm×10mm,在数百毫瓦功耗量级提供基于自主天文导航算法的恒星星图/太阳矢量/惯性姿态/目标提取跟踪等决策级信息,以及基于智能算法的目标识别、人脸检测、身份识别、多目标识别、路径规划、深度估计等决策级推理信息。端侧智能模块可基于核心系统接口拓展形成扩展系统,支持扩展部署应用级用户处理逻辑,灵活满足多层次导航及智能应用赋能需求。目前已开发多种可复用CMOS传感单元SIP(包括IMX335、S9132、HM0360、OV7251等)和多种可复用的FPGA/SOC端侧智能处理单元SIP(包括Ti60、GAP9、GD32E505等),同时端侧智能模块已赋能于多种类型天文敏感器系统、微型纳型无人机系统及地物导航系统。
个人简介:邢飞,清华大学长聘教授,清华大学微米纳米技术中心主任,长江学者特聘教授,科学探索奖获得者。主要从事智能微系统与航天应用研究,承担基础加强,科技部863、重点研发、自然科学基金重大仪器研发等项目。攻克高精度闭环光学测量微系统、微纳复眼测量微系统、MEMS调制光学测量等核心传感微系统理论,研制了系列光学敏感器,实时定姿定位一体化智能载荷,全球光学GNSS导航卫星等,研究成果实现了技术转让和批量应用,为我国相关领域研制了2000余台套空间光学姿态敏感器及微系统,在高分专项、互联网卫星、探月工程等任务中发挥了重要作用,并标准化产品实现了向德、英、美、日、西班牙等10余国出口,在国际上形成了品牌。研究成果获得国家技术发明二等奖2项,省部级一等奖4项。

刘 寅
牛芯半导体(深圳)有限公司常委副总
报告题目:高速接口技术助力人工智能
报告摘要:随着人工智能(AI)技术的快速发展,数据处理需求不断增长,而高速接口数据传输成为实现更快速、更高效AI系统的关键。类似NVLink一类的高速接口技术,在此背景下发挥着重要作用。通过提供高达300 GB/s的超高带宽和低延迟的数据传输能力,实现了GPU之间和GPU与其他设备之间的直接通信,从而极大地提升了系统的整体性能和效率。
在前景广阔的AI芯片领域,FPGA作为一种灵活可编程的硬件平台,具备较高的计算性能和可定制性,能够提供对AI算法的加速和优化;在AI应用中,可以用于实现神经网络加速器、高性能计算单元等,为计算密集型的AI任务提供高性能和低延迟的计算能力。而FPGA芯片必不可少的也是SerDes高速接口IP,其传输速率直接反映了FPGA与外界数据交换的能力。
可以说在人工智能领域,高速接口技术为分布式深度学习、大规模数据处理等关键任务提供了可靠的基础,加速了模型训练和推理的过程,同时降低了能耗和成本。随着人工智能应用场景的不断拓展,高速接口技术将继续发挥着重要作用,推动人工智能技术的创新与应用,助力人类社会迈向智能化未来。
牛芯半导体作为中国集成电路高速接口方向中坚力量,致力于半导体接口IP的开发和授权,业务涵盖SerDes、DDR、HBM等中高端接口IP,并基于接口技术为客户提供一站式芯片定制解决方案,目前已基于 180nm~12nm 工艺,积累多款接口 IP 产品,助推国产 FPGA、CPU、DSP 等重要芯片的自主可控进程,深耕高速接口事业助力人工智能发展进程。
个人简介:
1991~1995年 西安交通大学 电子系 学士
1995~1998年 清华大学 微电子所 硕士
1998~2001年 美国弗吉尼亚理工(Virginia Tech) 电子工程 硕士
- 作为国家重点专项“高端智能电视SOC关键IP核开发”的子课题负责人
- 主要技术专长在高速高精度的数模转换、高速串行数据处理,拥有三项美国专利
• IEEE资深会员,朝阳区“凤凰计划”海外高层次人才

谭闻德
清华大学博士研究生
报告题目:面向漏洞防护的处理器芯片方案
报告摘要:软件漏洞是计算机系统所面临的重要安全威胁之一,漏洞被攻击者利用后将导致多种严重不良后果。基于软硬件协同设计方法,在处理器芯片层面中加入软件漏洞防护原语,辅助软件阻断漏洞利用,是软件漏洞防护的行之有效的解决方案。本报告将介绍学术界和工业界近年来提出的此类面向漏洞防护的处理器芯片方案,以及本团队近期的研究进展。
个人简介:谭闻德,清华大学计算机科学与技术系博士研究生,师从吴建平院士、张超副教授,研究方向包括软硬件协同漏洞防护、计算机体系结构、计算机网络等。
大模型时代的图像技术创新与产业实践
论坛介绍
在AI大模型时代,图像图形技术的创新与产业实践显得尤为重要。百度技术论坛聚焦“大模型时代的图像图形技术创新与产业实践”,邀请百度AI专家、知名高校学者共同探讨图像图形技术在大模型背景下的最新发展和实践应用。与会者将有机会深入了解计算机视觉、智能无人系统视觉感知、3DGS、3D场景编辑、OCR以及数字人等技术在产业领域应用的最新成果。本论坛期望通过分享AI大模型在图像图形领域的产业实践,为学术界和产业界搭建开源开放的交流平台,共同推动图像图形技术在大模型时代的发展。
日程安排

论坛主席

王井东
百度计算机视觉首席科学家
个人简介:王井东,百度计算机视觉首席科学家。加入百度之前,曾任微软亚洲研究院视觉计算组首席研究员。研究领域为计算机视觉、深度学习及多媒体搜索。他的代表工作包括高分辨率神经网络(HRNet)、基于transformer attention的图像语义分割网络OCRNet、以及基于近邻图的大规模最近邻搜索(NGS,SPTAG)等。他曾担任过许多人工智能会议的领域主席,如 NerIPS、CVPR、ICCV、ECCV、AAAI、IJCAI、ACM MM等。他现在是IEEE TPAMI和IJCV的编委会成员。他是IEEE/IAPR 会士、ACM杰出会员、加拿大工程院院士。
论坛讲者信息

张鼎文
西北工业大学自动化学院 教授
报告题目:无人系统视觉感知初探
报告摘要:智能无人系统技术是指将人工智能技术与无人系统相结合,实现系统的自主性、智能化和自动化。智能无人系统技术可以应用于各个领域,例如无人车辆、无人飞行器、手术机器人等,在推动产业升级和国防安全方面具有重大意义。视觉感知技术被誉为无人系统之“眼”,通过对传感器采集的图像/视频进行处理与分析,视觉感知系统可以实现目标检测与跟踪、环境感知与地图构建等功能,为无人系统完成各项智能化任务提供坚实基础。在过去的二十年中,神经网络和图像/视频分析技术得到了突飞猛进的发展,然而,现有方法主要针对实验室受控环境下的视觉数据进行研究,在面对无人系统所工作的真实、开放环境时,仍面临重大挑战。本次报告将聚焦无人系统视觉感知领域的核心挑战,分享团队在该领域的初步探索,并对该领域未来的研究方向进行了分析和展望。
个人简介::张鼎文,西北工业大学自动化学院教授、博导,国家优秀青年科学基金获得者、科睿唯安“全球高被引科学家”,2015赴美国卡耐基梅隆大学进行为期2年的访问研究,致力于建立面向开放环境下、具备动态学习能力的新一代计算机视觉学习框架。迄今为止,作为第一作者/通讯作者在领域内国际重要期刊及会议发表学术论文60余篇,其中包含T-PAMI, IJCV, IEEE SPM, T-IP, CVPR, ICCV, Science China: Information Science等,曾入选中国博士后创新人才计划、AI 华人青年学者榜单, 获吴文俊人工智能优秀青年奖、2021 IEEE TCSVT最佳论文奖、中国图象图形学学会优秀博士论文奖等奖励。担任中国图象图形学学会青年工作委员会副秘书长、中国图象图形学学会优博俱乐部副主席,任IEEE TMM、TCSVT、PR等刊物(客座)编辑。

赵 晨
百度资深研发工程师
报告题目:3DGS在产业应用中的关键挑战与进展
报告摘要:3D高斯泼溅技术因其优秀的渲染效果和实时渲染能力,近期广受学术界和工业界的关注。在本次报告中,我们将从产业落地的视角讨论3DGS这一新的3D表征形式的关键挑战与进展。报告涵盖3DGS内容生产、编辑、驱动及移动端实时渲染解决方案等完整Pipeline构建中的技术点,分享我们对这一新表达形式的思考及相关工作进展。
个人简介:百度资深研发工程师,百度视觉技术部3D内容生成及渲染团队负责人,专注于计算机视觉与图形学技术在数字孪生、自动驾驶、导航导览及数字人等方面的融合性突破及落地应用探索,曾参与并主导Dumix AR平台、虚拟形象解决方案、大场景视觉定位系统、特效视频SDK等多项技术产品研发,发表多篇相关论文,申报相关专利达70+项,并已落地手机百度、百度地图、全民小视频、Apollo智慧座舱等,服务上亿用户。

吕鹏原
百度资深研发工程师
报告题目:大模型驱动下的OCR技术革新与前沿应用
报告摘要:在产业数字化转型和智能化升级的浪潮中,OCR技术始终扮演着举足轻重的角色。随着大模型和大数据的崛起,OCR技术的演进和应用前景正迎来前所未有的变革。本报告聚焦产业应用,深入剖析大模型时代下百度OCR的技术革新,以满足大规模用户和大数据场景下的多元化需求。我们也将首次揭秘百度OCR技术向实用级文档图像多模态理解迈进的大模型研发,包括其关键技术突破与产品应用尝试。百度OCR团队一直致力于研发前沿且实用的AI技术,打造覆盖多行业的OCR引擎,并推出多款普惠用户的文档智能产品,助力数字化时代的飞跃发展。
个人简介:吕鹏原,视觉技术部OCR基础技术负责人。他的研究领域主要聚焦于场景OCR和文档图像多模态理解大模型等方向,曾在TPAMI、CVPR、ECCV、ICML等顶级期刊会议发表多篇学术论文。相关技术落地于百度智能云,百度拍照搜索、百度网盘,小度词典笔等重要产品线。

周 航
百度资深研发工程师
报告题目:数字人驱动及3D生成技术进展
报告摘要:使用语音等模态信息输入,对人像的面部和动作进行驱动,是构建数字人的重要方式。本次演讲会介绍百度视觉技术部在数字人驱动方面的前沿进展,展示工业界该方面的最新技术成果,并介绍一种简单高效的3D内容生成的方案。
个人简介:周航,百度资深研发工程师,上海市浦东新区明珠计划菁英人才,负责视觉技术部数字人算法研发。博士毕业于香港中文大学,发表顶会论文30余篇,谷歌学术引用2200余次,在音视频多模态内容生成和数字人语音驱动,形象生成方面有丰富的研究和落地经验。

刘 偲
北京航空航天大学,教授
报告题目:图文自适应源驱动的3D场景编辑
报告摘要:本报告旨在解决图文自适应源驱动的3D场景编辑,并详细介绍了一种名为CustomNeRF的3D场景编辑框架。该框架对文本源驱动和图像源驱动的3D场景编辑进行了统一,并针对现有方法难以准确修改待编辑区域以及编辑后的结果存在多面问题这两个缺点,分别提出了局部-全局迭代编辑的训练方案以实现前景区域精准修改并保持背景不变,以及类引导正则化以利用生成模型中的类先验来实现不同视角间的一致性保持。
个人简介:刘偲,北航教授,国家优青。担任中国图象图形学学会理事、副秘书长。主持企业创新发展联合基金重点支持项目,担任科技创新2030—重大项目课题负责人。研究方向是具身智能和智能感知。发表CCF-A类论文80余篇(含TPAMI 13篇)。Google Scholar引用1.3万余次。获国家科技进步二等奖(9/10)、中国图象图形学学会自然科学奖一等奖(1/5)、CCF-腾讯犀牛鸟专利奖、吴文俊人工智能优青奖、石青云女科学家奖。获CCF-A类会议ACM MM最佳论文奖两次,获十余项CCF-A类会议竞赛冠军。